Storage Database
The Storage Database is a provably equivalent data structure that contains the subset of data that the original contract’s storage trie.
The key difference between the original storage trie and the storage database is the usage of a different encoding function, a different hash function and a different design of the tree. These changes make the new database much more friendly to "ZK queries".
Let’s see a concrete example for a small Merkle Paricia Trie (MPT) and the equivalent Storage Database that the ZK Coprocessor creates and maintains.
Storage Merkle Patricia Trie
In essence, a MPT looks like the following diagram. Note we are only proving a subset (we do not need to prove the whole storage trie yet). For example, the following diagram shows in red the entries of a Solidity mapping that we are processing.
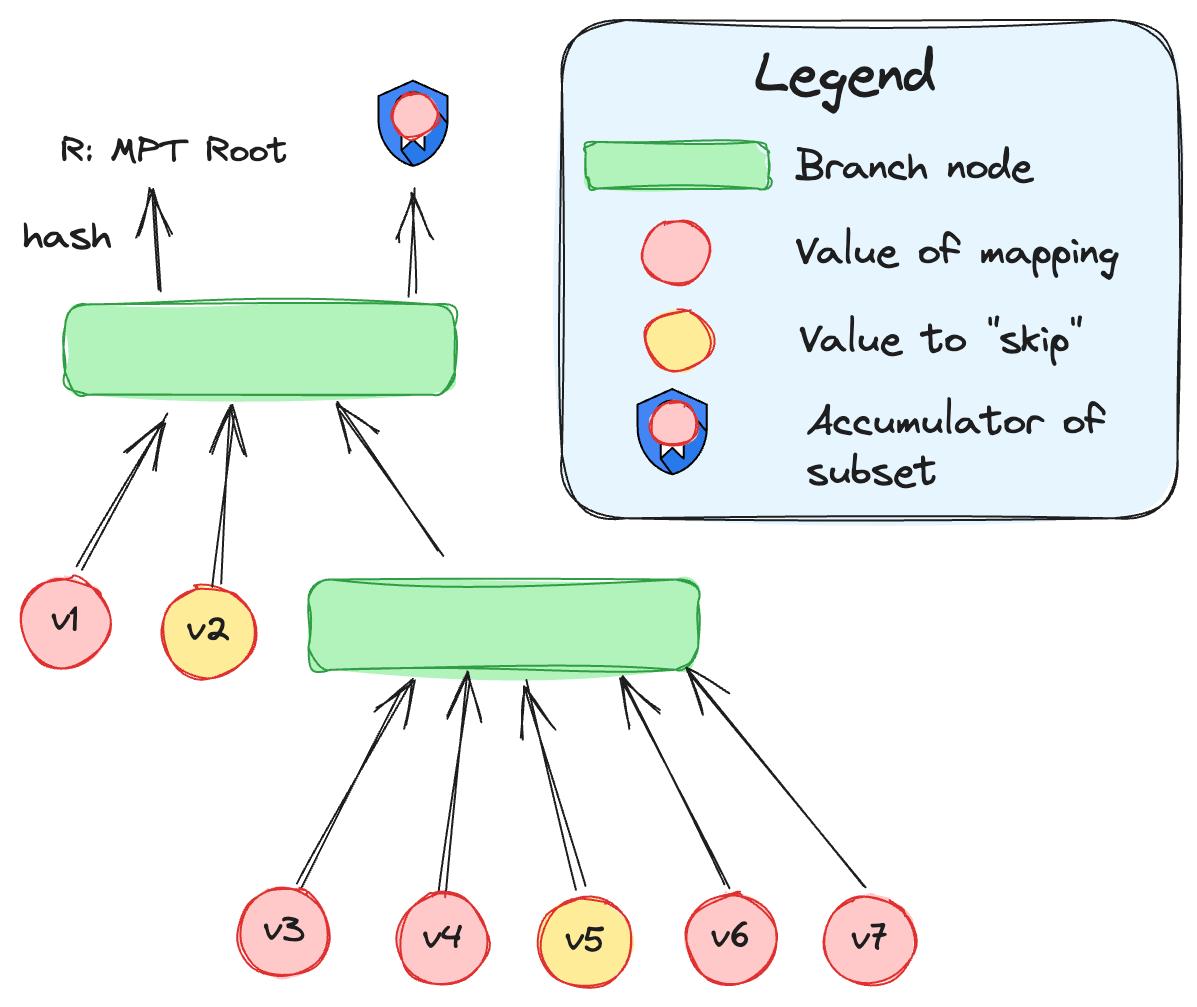
Recursive Proving
Each node in this MPT trie being "proved" by a SNARK/STARK that verifies the validity of the children's proofs and verifies the correct inclusion of the children in this node.
In simpler terms, we are "building the tree" using recursive proofs. The last proofs is the "root" proof.
Accumulator of the subset
The cryptographic proofs creates an accumulator of a subset of the leaves of interest, so we can prove in the equivalent storage database that the same leaves are included in both trees. An accumulator can succinctly represent a set of values. Hash functions are the most basic accumulators possible. However, because we need the order agnostic property, and to be efficiently verifiable in SNARKs, we are using multi set hashing over the ecgfp5 curve.
Lagrange Storage Database
The Coprocessor extracts the key/values pairs of interest from the storage trie and creates a new "ZK-friendly" Merkle tree from these values, and compute the digest of these pairs at the same time when constructing this Merkle Tree.
Accumulator of the subset
Since we are using the same subset, the accumulator’s final value is the same between the storage’s MPT and the ZK Coprocessor database. Note that both the accumulator and the Merkle root “represent” the same leaves, but accumulator is a special construction specifically used to prove equivalence with the MPT tree. The storage database is used in any and all subsequent queries by the ZK Coprocessor.
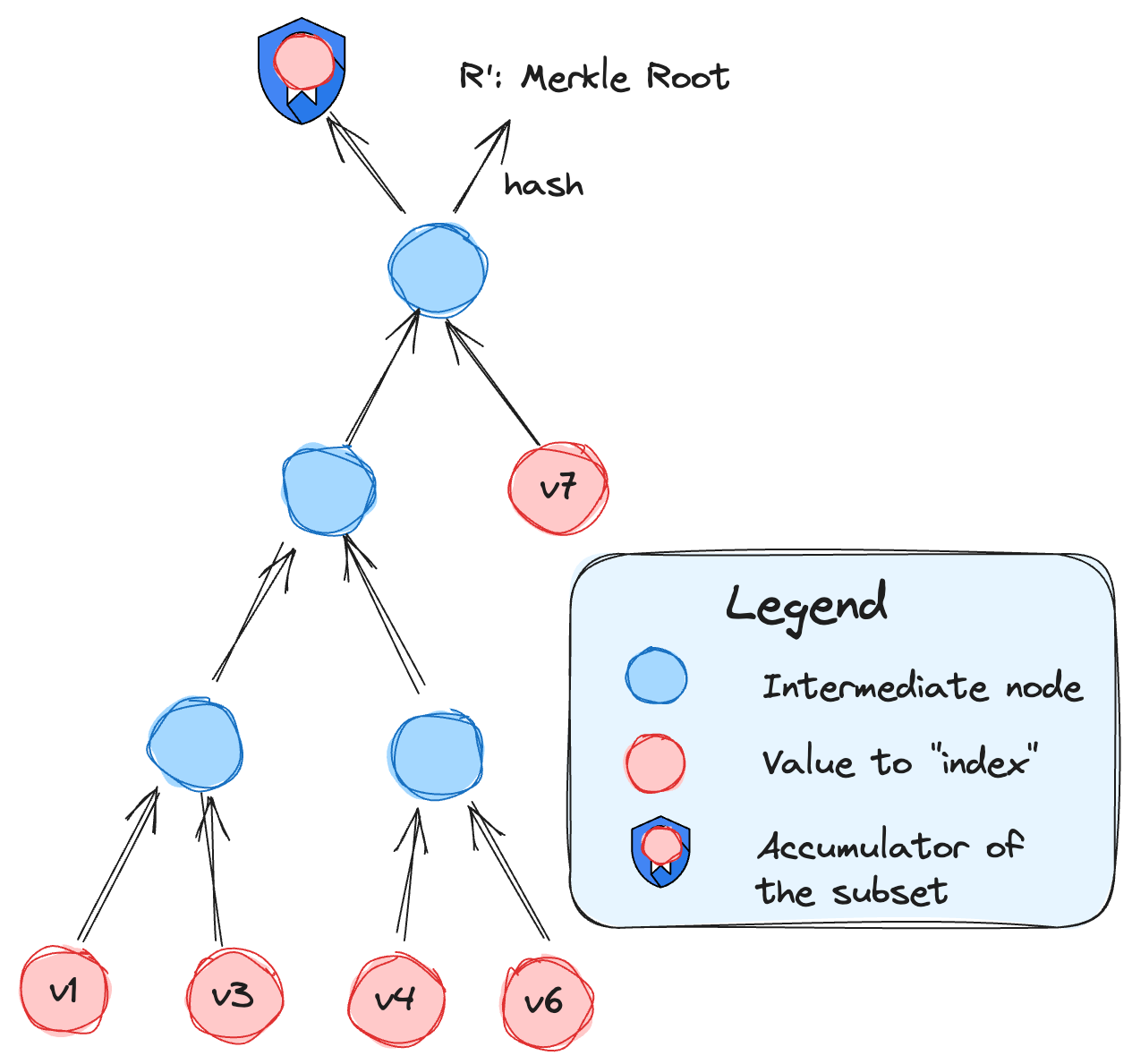
Structure of the ZK Coprocessor storage database
-
Merkle Tree: Since the ZK Coprocessor storage database is a Merkle tree (where data resides on the leaf, not internal nodes), unlike MPT, we do not have to care about the partial keys that are stored along the path to the leaf or the RLP encoding. These relaxations makes it easy to prove on the ZK Coprocessor structure.
-
Arity: Given we are only concerned with the subset, we can directly construct a full almost balanced tree from it. We chose arity = 2 since it lowers down the cost and complexity of our proofs (since we can enforce there are always 2 children, instead of potentially). Note this is a parameter of the ZK Coprocessor’s databases though.